1. Introducción
Vavr (anteriormente conocido como Javaslang) es una biblioteca funcional para Java 8+ que ofrece tipos de datos persistentes y estructuras de control funcionales.
1.1. Estructuras de Datos Funcionales en Java 8 con Vavr
Las lambdas (λ) de Java 8 nos permiten crear API maravillosas. Incrementan increíblemente la expresividad del lenguaje.
Vavr aprovechó las lambdas para introducir diversas características nuevas basadas en patrones funcionales. Una de ellas es una biblioteca de colecciones funcionales diseñada como un reemplazo para las colecciones estándar de Java.
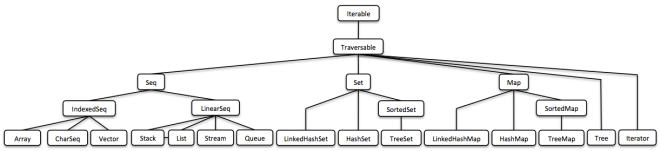
(Esta es solo una vista general; encontrarás una versión más detallada y legible a continuación.)
1.2. Programación Funcional
Antes de profundizar en los detalles sobre las estructuras de datos, quiero hablar sobre algunos conceptos básicos. Esto ayudará a entender por qué se creó Vavr y, en particular, por qué nuevas colecciones en Java eran necesarias.
1.2.1. Efectos Secundarios
Las aplicaciones Java suelen estar llenas de side-effects. Estos mutan algún tipo de estado, tal vez el mundo exterior. Los efectos secundarios comunes incluyen cambiar objetos o variables en el lugar, imprimir en la consola, escribir en un archivo de registro o en una base de datos. Los efectos secundarios se consideran perjudiciales si afectan la semántica de nuestro programa de manera no deseada.
Por ejemplo, si una función lanza una excepción y esta excepción es interpretada, se considera un efecto secundario que afecta nuestro programa. Además, las excepciones son como declaraciones goto no locales. Rompen el flujo de control normal. Sin embargo, las aplicaciones del mundo real realizan efectos secundarios.
int divide(int dividend, int divisor) {
// lanza una excepción si divisor es cero
return dividend / divisor;
}En un entorno funcional, estamos en la situación favorable de encapsular el efecto secundario en un Try:
// = Success(result) o Failure(exception)
Try<Integer> divide(Integer dividend, Integer divisor) {
return Try.of(() -> dividend / divisor);
}Esta versión de divide ya no lanza ninguna excepción. Hicimos que el posible fallo sea explícito al usar el tipo Try
1.2.2. Transparencia Referencial
Una función, o más generalmente una expresión, se denomina referencialmente transparente si una llamada puede ser reemplazada por su valor sin afectar el comportamiento del programa. Dicho de manera sencilla, dado el mismo input, la salida siempre será la misma.
// no es referencialmente transparente
Math.random();
// referencialmente transparente
Math.max(1, 2);Una función se llama pura si todas las expresiones involucradas son referencialmente transparentes. Una aplicación compuesta por funciones puras probablemente simplemente funcione si compila. Podemos razonar sobre ella. Las pruebas unitarias son fáciles de escribir y la depuración se convierte en un vestigio del pasado.
1.2.3. Pensar en Valores
Rich Hickey, el creador de Clojure, dio una charla excepcional sobre El Valor de los Valores. Los valores más interesantes son los valores immutable. La razón principal es que los valores inmutables:
-
Son intrínsecamente seguros para hilos y, por lo tanto, no necesitan sincronización.
-
Son estables en relación con equals and hashCode, lo que los convierte en claves de hash confiables.
-
No necesitan ser clonados.
-
Se comportan de manera segura con tipos al usarse en conversiones covariantes no verificadas (específicas de Java).
La clave para mejorar Java es usar valores inmutables junto con funciones referencialmente transparentes.
Vavr proporciona los controles y las colecciones necesarios para lograr este objetivo en la programación cotidiana en Java.
1.3. Estructuras de Datos en Resumen
La biblioteca de colecciones de Vavr incluye un conjunto rico de estructuras de datos funcionales construidas sobre lambdas. La única interfaz que comparten con las colecciones originales de Java es Iterable. La razón principal es que los métodos mutadores de las interfaces de colecciones de Java no devuelven un objeto del tipo de colección subyacente.
Veremos por qué esto es esencial observando los diferentes tipos de estructuras de datos.
1.3.1. Estructuras de Datos Mutables
Java es un lenguaje de programación orientado a objetos. Encapsulamos el estado en objetos para lograr ocultar los datos y proporcionamos métodos mutadores para controlar dicho estado. El framework de colecciones de Java (JCF) se basa en esta idea.
interface Collection<E> {
// elimina todos los elementos de esta colección
void clear();
}Hoy en día, considero que un tipo de retorno void es un indicio de mal diseño. Es evidencia de que ocurren efectos secundarios y de que el estado se está mutando. El estado mutable Shared es una fuente importante de fallos, no solo en un entorno concurrente.
1.3.2. Estructuras de Datos Inmutables
Las estructuras de datos Immutables no pueden modificarse después de su creación. En el contexto de Java, se utilizan ampliamente en forma de wrappers de colecciones.
List<String> list = Collections.unmodifiableList(otherList);
// Boom!
list.add("Por qué no?");Existen varias bibliotecas que nos proporcionan métodos de utilidad similares. El resultado siempre es una vista no modificable de la colección específica. Por lo general, lanzará una excepción en tiempo de ejecución si llamamos a un método mutador.
1.3.3. Estructuras de Datos Persistentes
Una estructura de datos persistente conserva la versión anterior de sí misma cuando se modifica, y por lo tanto es efectivamente inmutable. Las estructuras de datos completamente persistentes permiten tanto actualizaciones como consultas en cualquier versión.
Muchas operaciones realizan solo pequeños cambios. Simplemente copiar la versión anterior no sería eficiente. Para ahorrar tiempo y memoria, es crucial identificar las similitudes entre dos versiones y compartir la mayor cantidad de datos posible.
Este modelo no impone ningún detalle de implementación específico. Aquí es donde entran en juego las estructuras de datos funcionales.
1.4. Estructuras de Datos Funcionales
También conocidas como estructuras de datos puramente funcionales, son inmutables y persistentes. Los métodos de las estructuras de datos funcionales son referencialmente transparentes.
Vavr incluye una amplia gama de las estructuras de datos funcionales más utilizadas. Los siguientes ejemplos se explican en detalle.
1.4.1. Linked List
Una de las estructuras de datos funcionales más populares y también más simples es la lista enlazada (singly) linked List. Esta estructura tiene un elemento principal head y una lista tail (cola). Una lista enlazada se comporta como una pila (Stack) que sigue el método último en entrar, primero en salir (LIFO).
En Vavr, podemos instanciar una lista de la siguiente manera:
// = List(1, 2, 3)
List<Integer> list1 = List.of(1, 2, 3);Cada elemento de la lista forma un nodo separado de la lista. La cola (tail) del último elemento es Nil, que representa la lista vacía.

Esto nos permite compartir elementos entre diferentes versiones de la lista.
// = List(0, 2, 3)
List<Integer> list2 = list1.tail().prepend(0);El nuevo elemento principal 0 está vinculado a la cola de la lista original. La lista original permanece sin modificar.
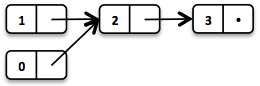
Estas operaciones se realizan en tiempo constante, es decir, son independientes del tamaño de la lista. La mayoría de las otras operaciones toman tiempo lineal. En Vavr, esto se expresa mediante la interfaz LinearSeq, que ya conocemos de Scala.
Si necesitamos estructuras de datos que permitan consultas en tiempo constante, Vavr ofrece Array y Vector. Ambos tienen capacidades de acceso aleatorio.
El tipo Array está respaldado por un array de objetos de Java. Las operaciones de inserción y eliminación toman tiempo lineal. Él Vector está entre Array y List. Tiene un buen rendimiento tanto en acceso aleatorio como en modificaciones.
De hecho, la lista enlazada también puede utilizarse para implementar una estructura de datos tipo cola (Queue).
1.4.2. Queue
Una cola funcional muy eficiente puede implementarse utilizando dos listas enlazadas. La lista front contiene los elementos que se eliminan de la cola, mientras que la lista rear contiene los elementos que se agregan. Ambas operaciones, enqueue y dequeue, se realizan en tiempo O(1).
Queue<Integer> queue = Queue.of(1, 2, 3)
.enqueue(4)
.enqueue(5);La cola inicial se crea con tres elementos. Luego, se agregan dos elementos en la lista rear.
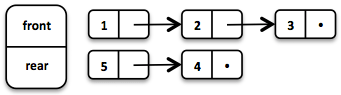
Si la lista front se queda sin elementos al hacer dequeue, la lista rear se invierte y se convierte en la nueva lista front.
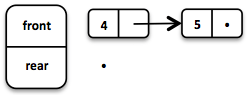
Al hacer dequeue de un elemento, obtenemos un par que incluye el primer elemento y la cola restante. Es necesario devolver la nueva versión de la cola porque las estructuras de datos funcionales son inmutables y persistentes. La cola original no se ve afectada.
Queue<Integer> queue = Queue.of(1, 2, 3);
// = (1, Queue(2, 3))
Tuple2<Integer, Queue<Integer>> dequeued =
queue.dequeue();¿Qué sucede cuando la cola está vacía? En ese caso, dequeue() lanzará una excepción NoSuchElementException. Para hacerlo de manera funcional, esperaríamos más bien un resultado opcional.
// = Some((1, Queue()))
Queue.of(1).dequeueOption();
// = None
Queue.empty().dequeueOption();Un resultado opcional puede procesarse aún más, ya sea que esté vacío o no.
// = Queue(1)
Queue<Integer> queue = Queue.of(1);
// = Some((1, Queue()))
Option<Tuple2<Integer, Queue<Integer>>> dequeued =
queue.dequeueOption();
// = Some(1)
Option<Integer> element = dequeued.map(Tuple2::_1);
// = Some(Queue())
Option<Queue<Integer>> remaining =
dequeued.map(Tuple2::_2);1.4.3. Conjuntos Ordenados (Sorted Set)
Los conjuntos ordenados son estructuras de datos que se utilizan con más frecuencia que las colas. Utilizamos árboles binarios de búsqueda para modelarlos de manera funcional. Estos árboles están compuestos por nodos que pueden tener hasta dos hijos y valores en cada nodo.
Construimos árboles binarios de búsqueda bajo la presencia de un orden, representado por un Comparator. Todos los valores del subárbol izquierdo de cualquier nodo dado son estrictamente menores que el valor del nodo. Todos los valores del subárbol derecho son estrictamente mayores.
// = TreeSet(1, 2, 3, 4, 6, 7, 8)
SortedSet<Integer> xs = TreeSet.of(6, 1, 3, 2, 4, 7, 8);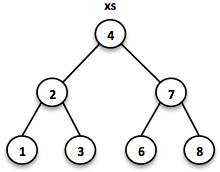
Las búsquedas en este tipo de árboles se realizan en tiempo O(log n). Comenzamos la búsqueda en la raíz y determinamos si encontramos el elemento. Debido al orden total de los valores, sabemos hacia dónde buscar a continuación, en la rama izquierda o derecha del árbol actual.
// = TreeSet(1, 2, 3);
SortedSet<Integer> set = TreeSet.of(2, 3, 1, 2);
// = TreeSet(3, 2, 1);
Comparator<Integer> c = (a, b) -> b - a;
SortedSet<Integer> reversed = TreeSet.of(c, 2, 3, 1, 2);La mayoría de las operaciones sobre árboles son intrínsecamente recursivas. La función de inserción se comporta de manera similar a la función de búsqueda. Cuando se alcanza el final de un camino de búsqueda, se crea un nuevo nodo y se reconstruye todo el camino hasta la raíz. Siempre que sea posible, los nodos hijos existentes se reutilizan. Por lo tanto, la operación de inserción toma tiempo y espacio O(log n).
// = TreeSet(1, 2, 3, 4, 5, 6, 7, 8)
SortedSet<Integer> ys = xs.add(5);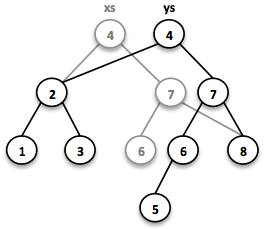
Para mantener las características de rendimiento de un árbol binario de búsqueda, debe mantenerse equilibrado. Todos los caminos desde la raíz hasta una hoja deben tener aproximadamente la misma longitud.
En Vavr, implementamos un árbol binario de búsqueda basado en un Red/Black Tree (Árbol Rojo/Negro). Este utiliza una estrategia de coloración específica para mantener el equilibrio del árbol durante las operaciones de inserción y eliminación. Para obtener más información sobre este tema, se recomienda leer el libro Purely Functional Data Structures de Chris Okasaki.
1.5. Estado de las Colecciones
En general, estamos observando una convergencia entre los lenguajes de programación. Las características buenas prevalecen, mientras que otras desaparecen. Sin embargo, Java es diferente: está destinado a ser compatible hacia atrás para siempre. Esa es una fortaleza, pero también ralentiza su evolución.
Las expresiones lambda acercaron a Java y Scala, pero aún son muy diferentes. Martin Odersky, el creador de Scala, mencionó recientemente en su charla magistral en la BDSBTB 2015 el estado de las colecciones en Java 8.
Describió el Stream de Java como una forma elegante de un iterador. La API de Stream de Java 8 es un ejemplo de una colección elevada. Lo que hace es definir una computación y vincularla a una colección específica en otro paso explícito.
// i + 1
i.prepareForAddition()
.add(1)
.mapBackToInteger(Mappers.toInteger())Así es como funciona la nueva API de Stream en Java 8. Es una capa computacional encima de las conocidas colecciones de Java.
// = ["1", "2", "3"] en Java 8
Arrays.asList(1, 2, 3)
.stream()
.map(Object::toString)
.collect(Collectors.toList())Vavr se inspira enormemente en Scala. Así es como debería verse el ejemplo anterior en Java 8.
// = Stream("1", "2", "3") en Vavr
Stream.of(1, 2, 3).map(Object::toString)En el último año, hemos dedicado mucho esfuerzo a implementar la biblioteca de colecciones de Vavr. Comprende los tipos de colecciones más ampliamente utilizados.
1.5.1. Seq
Comenzamos nuestro viaje implementando tipos secuenciales. Ya describimos la lista enlazada anteriormente. Luego siguió el Stream, una lista enlazada perezosa (lazy) que nos permite procesar secuencias de elementos posiblemente infinitas.
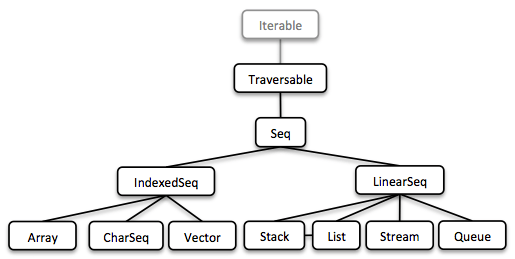
Todas las colecciones son Iterable y, por lo tanto, pueden usarse en bucles for mejorados.
for (String s : List.of("Java", "Advent")) {
// efectos secundarios y mutación
}Podemos lograr lo mismo internalizando el bucle e inyectando el comportamiento usando una lambda.
List.of("Java", "Advent").forEach(s -> {
// efectos secundarios y mutación
});De todos modos, como vimos anteriormente, preferimos expresiones que devuelvan un valor sobre instrucciones que no devuelven nada. Observando un ejemplo simple, pronto reconoceremos que las instrucciones añaden ruido y separan lo que pertenece junto.
String join(String... words) {
StringBuilder builder = new StringBuilder();
for(String s : words) {
if (builder.length() > 0) {
builder.append(", ");
}
builder.append(s);
}
return builder.toString();
}Las colecciones de Vavr nos proporcionan muchas funciones para operar sobre los elementos subyacentes. Esto nos permite expresar las cosas de manera muy concisa.
String join(String... words) {
return List.of(words)
.intersperse(", ")
.foldLeft(new StringBuilder(), StringBuilder::append)
.toString();
}La mayoría de los objetivos se pueden lograr de diversas maneras usando Vavr. Aquí reducimos todo el cuerpo del método a llamadas de función fluidas en una instancia de List. Incluso podríamos eliminar todo el método y usar directamente nuestra lista para obtener el resultado de la computación.
List.of(words).mkString(", ");En una aplicación del mundo real, ahora podemos reducir drásticamente el número de líneas de código y, por lo tanto, disminuir el riesgo de errores.
1.5.2. Set y Map
Las secuencias son geniales. Pero, para ser completos, una biblioteca de colecciones también necesita diferentes tipos de Set y Map.
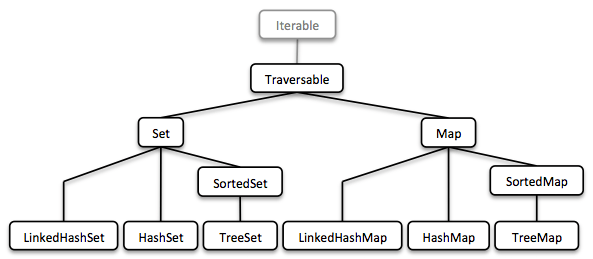
Describimos cómo modelar conjuntos ordenados con estructuras de árboles binarios. Un Map ordenado no es más que un Set ordenado que contiene pares clave-valor y que tiene un orden para las claves.
La implementación de HashMap se respalda mediante un Hash Array Mapped Trie (HAMT). En consecuencia, el HashSet está respaldado por un HAMT que contiene pares clave-clave.
Nuestro Map no tiene un tipo especial de Entry para representar pares clave-valor. En su lugar, usamos Tuple2, que ya es parte de Vavr. Los campos de un Tuple están enumerados.
// = (1, "A")
Tuple2<Integer, String> entry = Tuple.of(1, "A");
Integer key = entry._1;
String value = entry._2;Los Map y Tuple se utilizan ampliamente en Vavr. Los Tuple son esenciales para manejar tipos de retorno con múltiples valores de forma general.
// = HashMap((0, List(2, 4)), (1, List(1, 3)))
List.of(1, 2, 3, 4).groupBy(i -> i % 2);
// = List((a, 0), (b, 1), (c, 2))
List.of('a', 'b', 'c').zipWithIndex();En Vavr, exploramos y probamos nuestra biblioteca implementando los 99 problemas de Euler. Es una excelente prueba de concepto. No dudes en enviar solicitudes de pull.
2. Comenzando
Los proyectos que incluyan Vavr deben apuntar como mínimo a Java 1.8.
El archivo .jar está disponible en Maven Central.
2.1. Gradle
dependencies {
compile "io.vavr:vavr:0.10.5"
}Gradle 7+
dependencies {
implementation "io.vavr:vavr:0.10.5"
}2.2. Maven
<dependencies>
<dependency>
<groupId>io.vavr</groupId>
<artifactId>vavr</artifactId>
<version>0.10.4</version>
</dependency>
</dependencies>2.3. Independiente
Debido a que Vavr no depende de ninguna biblioteca (aparte de la JVM), puedes agregarlo fácilmente como un archivo .jar independiente a tu classpath.
2.4. Snapshots
Las versiones en desarrollo se pueden encontrar aquí.
2.4.1. Gradle
Agrega el repositorio adicional de snapshots en tu archivo build.gradle:
repositories {
(...)
maven { url "https://oss.sonatype.org/content/repositories/snapshots" }
}2.4.2. Maven
Asegúrate de que tu archivo ~/.m2/settings.xml contenga lo siguiente:
<profiles>
<profile>
<id>allow-snapshots</id>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
<repositories>
<repository>
<id>snapshots-repo</id>
<url>https://oss.sonatype.org/content/repositories/snapshots</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
</profile>
</profiles>3. Guía de Uso
Vavr incluye representaciones bien diseñadas de algunos de los tipos más básicos que, aparentemente, faltan o son rudimentarios en Java: Tuple, Value y λ.
En Vavr, todo se construye sobre estos tres bloques básicos:
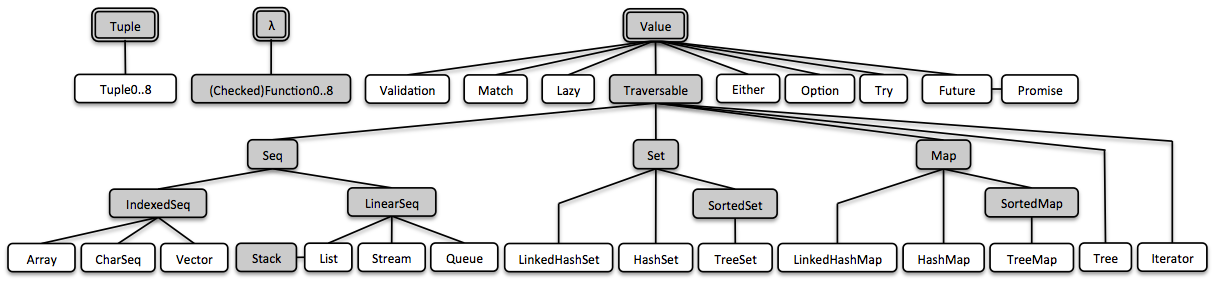
3.1. Tuplas
Java carece de una noción general de tuplas. Una tupla combina un número fijo de elementos para que puedan ser tratados como un todo. A diferencia de un array o lista, una tupla puede contener objetos de diferentes tipos, pero también son inmutables.
Las tuplas tienen tipos como Tuple1, Tuple2, Tuple3 y así sucesivamente. Actualmente, hay un límite máximo de 8 elementos. Para acceder a los elementos de una tupla t, puedes usar el método t._1 para acceder al primer elemento, t._2 para el segundo, y así sucesivamente.
3.1.1. Crear una tupla
Aquí tienes un ejemplo de cómo crear una tupla que contiene un String y un Integer:
// (Java, 8)
Tuple2<String, Integer> java8 = Tuple.of("Java", 8); (1)
// "Java"
String s = java8._1; (2)
// 8
Integer i = java8._2; (3)| 1 | Se crea una tupla mediante el método de fábrica estático Tuple.of() |
| 2 | Obtén el primer elemento de esta tupla. |
| 3 | Obtén el segundo elemento de esta tupla. |
3.1.2. Mapear una tupla elemento por elemento
El mapeo elemento por elemento evalúa una función por cada elemento de la tupla, devolviendo otra tupla.
// (vavr, 1)
Tuple2<String, Integer> that = java8.map(
s -> s.substring(2) + "vr",
i -> i / 8
);3.1.3. Mapear una tupla usando un único mapeador
También es posible mapear una tupla usando una sola función de mapeo.
// (vavr, 1)
Tuple2<String, Integer> that = java8.map(
(s, i) -> Tuple.of(s.substring(2) + "vr", i / 8)
);3.1.4. Transformar una tupla
La transformación crea un nuevo tipo basado en el contenido de la tupla.
// "vavr 1"
String that = java8.apply(
(s, i) -> s.substring(2) + "vr " + i / 8
);3.2. Funciones
La programación funcional se centra en los valores y en la transformación de valores mediante funciones. Java 8 solo proporciona una Function que acepta un parámetro y una BiFunction que acepta dos parámetros. Vavr proporciona funciones con un límite de hasta 8 parámetros. Las interfaces funcionales se denominan Function0, Function1, Function2, Function3 y así sucesivamente. Si necesitas una función que lance una excepción comprobada, puedes usar CheckedFunction1, CheckedFunction2 y así sucesivamente.
La siguiente expresión lambda crea una función para sumar dos enteros:
// sum.apply(1, 2) = 3
Function2<Integer, Integer, Integer> sum = (a, b) -> a + b;Esto es una abreviatura para la siguiente definición de clase anónima:
Function2<Integer, Integer, Integer> sum = new Function2<Integer, Integer, Integer>() {
@Override
public Integer apply(Integer a, Integer b) {
return a + b;
}
};También puedes usar el método de fábrica estático Function3.of(…) para crear una función a partir de cualquier referencia de método.
Function3<String, String, String, String> function3 =
Function3.of(this::methodWhichAccepts3Parameters);De hecho, las interfaces funcionales de Vavr son interfaces funcionales de Java 8 potenciadas. También ofrecen características como:
-
Composición
-
Elevación (Lifting)
-
Currificación (Currying)
-
Memoización
3.2.1. Composición
Puedes componer funciones. En matemáticas, la composición de funciones es la aplicación de una función al resultado de otra para producir una tercera función. Por ejemplo, las funciones f : X → Y and g : Y → Z pueden componerse para generar una función h: g(f(x)) que mapea X → Z.
Puedes usar andThen:
Function1<Integer, Integer> plusOne = a -> a + 1;
Function1<Integer, Integer> multiplyByTwo = a -> a * 2;
Function1<Integer, Integer> add1AndMultiplyBy2 = plusOne.andThen(multiplyByTwo);
then(add1AndMultiplyBy2.apply(2)).isEqualTo(6);o compose:
Function1<Integer, Integer> add1AndMultiplyBy2 = multiplyByTwo.compose(plusOne);
then(add1AndMultiplyBy2.apply(2)).isEqualTo(6);3.2.2. Elevación (Lifting)
Puedes elevar una función parcial a una función total que devuelve un resultado de tipo Option. El término partial function proviene de las matemáticas. Una función parcial de X a Y es una función f: X′ → Y, para algún subconjunto X′ de X. Generaliza el concepto de una función f: X → Y al no forzar que f asocie cada elemento de X a un elemento de Y. Esto significa que una función parcial funciona correctamente solo para algunos valores de entrada. Si se llama a la función con un valor de entrada no permitido, normalmente lanzará una excepción.
El siguiente método divide es una función parcial que solo acepta divisores distintos de cero.
Function2<Integer, Integer, Integer> divide = (a, b) -> a / b;Usamos lift para convertir divide en una función total que está definida para todas las entradas.
Function2<Integer, Integer, Option<Integer>> safeDivide = Function2.lift(divide);
// = None
Option<Integer> i1 = safeDivide.apply(1, 0); (1)
// = Some(2)
Option<Integer> i2 = safeDivide.apply(4, 2); (2)| 1 | Una función elevada devuelve None en lugar de lanzar una excepción, si la función se invoca con valores de entrada no permitidos. |
| 2 | Una función elevada devuelve Some, si la función se invoca con valores de entrada permitidos. |
El siguiente método sum es una función parcial que solo acepta valores de entrada positivos.
int sum(int first, int second) {
if (first < 0 || second < 0) {
throw new IllegalArgumentException("Only positive integers are allowed"); (1)
}
return first + second;
}| 1 | La función sum lanza una excepción IllegalArgumentException para valores de entrada negativos. |
Podemos elevar el método sum proporcionando la referencia al método.
Function2<Integer, Integer, Option<Integer>> sum = Function2.lift(this::sum);
// = None
Option<Integer> optionalResult = sum.apply(-1, 2); (1)| 1 | La función elevada captura la excepción IllegalArgumentException y la mapea a None. |
3.2.3. Aplicación Parcial
La aplicación parcial te permite derivar una nueva función a partir de una existente fijando algunos valores. Puedes fijar uno o más parámetros, y el número de parámetros fijados define la aridad de la nueva función, de manera que new arity = (original arity - fixed parameters). Los parámetros se asignan de izquierda a derecha.
Function2<Integer, Integer, Integer> sum = (a, b) -> a + b;
Function1<Integer, Integer> add2 = sum.apply(2); (1)
then(add2.apply(4)).isEqualTo(6);| 1 | El primer parámetro a se fija al valor 2. |
Esto puede demostrarse fijando los primeros tres parámetros de una Function5, lo que resulta en una Function2.
Function5<Integer, Integer, Integer, Integer, Integer, Integer> sum = (a, b, c, d, e) -> a + b + c + d + e;
Function2<Integer, Integer, Integer> add6 = sum.apply(2, 3, 1); (1)
then(add6.apply(4, 3)).isEqualTo(13);| 1 | Los parámetros a, b y c se fijan a los valores 2, 3 y 1, respectivamente. |
La aplicación parcial difiere de la Currificación (Currying), como se explorará en la sección correspondiente.
3.2.4. Currificación (Currying)
La currificación es una técnica que permite aplicar parcialmente una función fijando un valor para uno de los parámetros, lo que da como resultado una función Function1 que devuelve otra función Function1.
Cuando una Function2 es curried, el resultado es indistinguible de la aplicación parcial de una Function2 ya que ambas producen una función de aridad 1.
Function2<Integer, Integer, Integer> sum = (a, b) -> a + b;
Function1<Integer, Integer> add2 = sum.curried().apply(2); (1)
then(add2.apply(4)).isEqualTo(6);| 1 | El primer parámetro a se fija al valor 2. |
Podrás notar que, aparte del uso de .curried(), este código es idéntico al ejemplo de aridad 2 dado en Aplicación Parcial. Con funciones de mayor aridad, la diferencia se vuelve evidente.
Function3<Integer, Integer, Integer, Integer> sum = (a, b, c) -> a + b + c;
final Function1<Integer, Function1<Integer, Integer>> add2 = sum.curried().apply(2);(1)
then(add2.apply(4).apply(3)).isEqualTo(9);(2)| 1 | Nota la presencia de funciones adicionales en los parámetros. |
| 2 | Las llamadas posteriores a apply devuelven otra Function1, excepto en la llamada final. |
3.2.5. Memoización
La memoización es una forma de almacenamiento en caché. Una función memoizada se ejecuta solo una vez y luego devuelve el resultado desde una caché.
El siguiente ejemplo calcula un número aleatorio en la primera invocación y devuelve el número almacenado en caché en la segunda invocación.
Function0<Double> hashCache =
Function0.of(Math::random).memoized();
double randomValue1 = hashCache.apply();
double randomValue2 = hashCache.apply();
then(randomValue1).isEqualTo(randomValue2);3.3. Values
En un entorno funcional, vemos un valor como una especie de forma normal, una expresión que no puede evaluarse más. En Java, expresamos esto haciendo que el estado de un objeto sea final y lo llamamos objeto immutable.
El valor funcional de Vavr abstrae sobre objetos inmutables. Las operaciones de escritura eficientes se logran compartiendo memoria inmutable entre instancias. ¡Esto nos proporciona seguridad en hilos automáticamente!
3.3.1. Option
Option es un tipo de contenedor monádico que representa un valor opcional. Las instancias de Option son ya sea una instancia de Some o None.
// optional *value*, no more nulls
Option<T> option = Option.of(...);Si vienes a Vavr después de usar la clase Optional de Java, hay una diferencia crucial. En Optional, una llamada a .map que resulta en un valor null producirá un Optional vacío. En Vavr, esto generaría un Some(null), lo que podría llevar a un NullPointerException.
Usando Optional, este escenario es válido.
Optional<String> maybeFoo = Optional.of("foo"); (1)
then(maybeFoo.get()).isEqualTo("foo");
Optional<String> maybeFooBar = maybeFoo.map(s -> (String)null) (2)
.map(s -> s.toUpperCase() + "bar");
then(maybeFooBar.isPresent()).isFalse();| 1 | La opción es Some("foo"). |
| 2 | La opción resultante se vuelve vacía aquí. |
Usando la Option de Vavr, el mismo escenario resultará en un NullPointerException.
Option<String> maybeFoo = Option.of("foo"); (1)
then(maybeFoo.get()).isEqualTo("foo");
try {
maybeFoo.map(s -> (String)null) (2)
.map(s -> s.toUpperCase() + "bar"); (3)
Assert.fail();
} catch (NullPointerException e) {
// this is clearly not the correct approach
}| 1 | La opción es Some("foo") |
| 2 | La opción resultante es Some(null) |
| 3 | TLa llamada a s.toUpperCase() se invoca sobre un null |
Esto puede parecer que la implementación de Vavr está rota, pero en realidad no lo está. Más bien, se adhiere al requisito de una mónada (monad) de mantener el contexto computacional al llamar a .map. En términos de una Option, esto significa que llamar a .map en un Some dará como resultado un Some y llamar a .map en un None dará como resultado un None. En el ejemplo de Optional de Java mencionado anteriormente, ese contexto cambió de un Some a un None.
Esto puede parecer que hace que Option sea inútil, pero en realidad te obliga a prestar atención a las posibles ocurrencias de null y a manejarlas adecuadamente en lugar de aceptarlas sin saberlo. La forma correcta de manejar las ocurrencias de null es usar flatMap.
Option<String> maybeFoo = Option.of("foo"); (1)
then(maybeFoo.get()).isEqualTo("foo");
Option<String> maybeFooBar = maybeFoo.map(s -> (String)null) (2)
.flatMap(s -> Option.of(s) (3)
.map(t -> t.toUpperCase() + "bar"));
then(maybeFooBar.isEmpty()).isTrue();| 1 | La opción es Some("foo") |
| 2 | La opción resultante es Some(null) |
| 3 | s, que es null, se convierte en None |
Alternativamente, mueve el .flatMap para que esté ubicado junto al valor que posiblemente sea null.
Option<String> maybeFoo = Option.of("foo"); (1)
then(maybeFoo.get()).isEqualTo("foo");
Option<String> maybeFooBar = maybeFoo.flatMap(s -> Option.of((String)null)) (2)
.map(s -> s.toUpperCase() + "bar");
then(maybeFooBar.isEmpty()).isTrue();| 1 | La opción es Some("foo") |
| 2 | La opción resultante es None |
Esto se explora en más detalle en el blog de Vavr.
3.3.2. Try
Try es un tipo de contenedor monádico que representa una computación que puede resultar en una excepción o devolver un valor calculado exitosamente. Es similar a Either, pero semánticamente diferente. Una instancia de Try puede ser una instancia de Success o Failure.
// no need to handle exceptions
Try.of(() -> bunchOfWork()).getOrElse(other);import static io.vavr.API.*; // $, Case, Match
import static io.vavr.Predicates.*; // instanceOf
A result = Try.of(this::bunchOfWork)
.recover(x -> Match(x).of(
Case($(instanceOf(Exception_1.class)), t -> somethingWithException(t)),
Case($(instanceOf(Exception_2.class)), t -> somethingWithException(t)),
Case($(instanceOf(Exception_n.class)), t -> somethingWithException(t))
))
.getOrElse(other);3.3.3. Lazy
Lazy es un tipo de contenedor monádico que representa un valor evaluado de forma perezosa (lazy). En comparación con un Supplier, Lazy realiza memoización, es decir, se evalúa solo una vez y, por lo tanto, es referencialmente transparente.
Lazy<Double> lazy = Lazy.of(Math::random);
lazy.isEvaluated(); // = false
lazy.get(); // = 0.123 (random generated)
lazy.isEvaluated(); // = true
lazy.get(); // = 0.123 (memoized)También puedes crear un valor realmente perezoso (lazy) (esto solo funciona con interfaces):
CharSequence chars = Lazy.val(() -> "Yay!", CharSequence.class);3.3.4. Either
Either representa un valor de dos tipos posibles. Un Either es, o bien un Left, o bien un Right. Si un Either dado es un Right y se proyecta a un Left, las operaciones de Left no tienen efecto sobre el valor de Right. Si un Either dado es un Left y se proyecta a un Right, las operaciones de Right no tienen efecto sobre el valor de Left. Si un Left se proyecta a un Left, o un Right se proyecta a un Right, las operaciones sí tienen efecto.
Ejemplo: Una función compute(), que da como resultado un valor de tipo Integer (en el caso de éxito) o un mensaje de error de tipo String (en el caso de fallo). Por convención, el caso de éxito es Right y el de fallo es Left.
Either<String,Integer> value = compute().right().map(i -> i * 2).toEither();Si el resultado de compute() es Right(1), el valor es Right(2).
Si el resultado de compute() es Left("error"), el valor es Left("error").
3.3.5. Future
Un Future es el resultado de una computación que estará disponible en algún momento. Todas las operaciones proporcionadas son no bloqueantes. El ExecutorService subyacente se utiliza para ejecutar controladores asíncronos, por ejemplo, mediante onComplete(…).
Un Future tiene dos estados: pendiente y completado.
Pendiente: La computación está en curso. Solo un Future pendiente puede completarse o cancelarse.
Completado: La computación finalizó exitosamente con un resultado, falló con una excepción o fue cancelada.
Los callbacks pueden registrarse en un Future en cualquier momento. Estas acciones se ejecutan tan pronto como el Future se completa. Una acción registrada en un Future completado se ejecuta inmediatamente. La acción puede ejecutarse en un hilo separado, dependiendo del ExecutorService subyacente. Las acciones registradas en un Future cancelado se ejecutan con el resultado fallido.
// future *value*, result of an async calculation
Future<T> future = Future.of(...);3.3.6. Validación (Validation)
El control de validación (Validation) es un funtor aplicativo que facilita la acumulación de errores. Al intentar componer mónadas, el proceso de combinación se detendrá en el primer error encontrado. Sin embargo, Validation continuará procesando las funciones de combinación, acumulando todos los errores. Esto es especialmente útil al validar múltiples campos, como un formulario web, cuando deseas conocer todos los errores encontrados en lugar de uno por uno.
Ejemplo: Obtenemos los campos name y age de un formulario web y queremos crear una instancia válida de Person, o devolver la lista de errores de validación.
PersonValidator personValidator = new PersonValidator();
// Valid(Person(John Doe, 30))
Validation<Seq<String>, Person> valid = personValidator.validatePerson("John Doe", 30);
// Invalid(List(Name contains invalid characters: '!4?', Age must be greater than 0))
Validation<Seq<String>, Person> invalid = personValidator.validatePerson("John? Doe!4", -1);Un valor válido está contenido en una instancia de Validation.Valid, mientras que una lista de errores de validación está contenida en una instancia de Validation.Invalid.
El siguiente validador se utiliza para combinar diferentes resultados de validación en una sola instancia de Validation.
class PersonValidator {
private static final String VALID_NAME_CHARS = "[a-zA-Z ]";
private static final int MIN_AGE = 0;
public Validation<Seq<String>, Person> validatePerson(String name, int age) {
return Validation.combine(validateName(name), validateAge(age)).ap(Person::new);
}
private Validation<String, String> validateName(String name) {
return CharSeq.of(name).replaceAll(VALID_NAME_CHARS, "").transform(seq -> seq.isEmpty()
? Validation.valid(name)
: Validation.invalid("Name contains invalid characters: '"
+ seq.distinct().sorted() + "'"));
}
private Validation<String, Integer> validateAge(int age) {
return age < MIN_AGE
? Validation.invalid("Age must be at least " + MIN_AGE)
: Validation.valid(age);
}
}
Si la validación tiene éxito, es decir, si los datos de entrada son válidos, entonces se crea una instancia de Person con los campos name y age proporcionados.
class Person {
public final String name;
public final int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person(" + name + ", " + age + ")";
}
}
3.4. Colecciones
Se ha dedicado mucho esfuerzo a diseñar una biblioteca de colecciones completamente nueva para Java que cumpla con los requisitos de la programación funcional, especialmente la inmutabilidad.
El Stream de Java eleva una computación a una capa diferente y se vincula a una colección específica en otro paso explícito. Con Vavr, no necesitamos todo este código adicional repetitivo (boilerplate).
Las nuevas colecciones están basadas en java.lang.Iterable, lo que permite aprovechar un estilo de iteración simplificado.
// 1000 random numbers
for (double random : Stream.continually(Math::random).take(1000)) {
...
}TraversableOnce tiene una gran cantidad de funciones útiles para operar en la colección. Su API es similar a java.util.stream.Stream, pero es más madura.
3.4.1. List
La List de Vavr es una lista enlazada inmutable. Las mutaciones crean nuevas instancias. La mayoría de las operaciones se realizan en tiempo lineal. Las operaciones consecutivas se ejecutan una por una.
Java 8
Arrays.asList(1, 2, 3).stream().reduce((i, j) -> i + j);IntStream.of(1, 2, 3).sum();Vavr
// io.vavr.collection.List
List.of(1, 2, 3).sum();3.4.2. Stream
La implementación de io.vavr.collection.Stream es una lista enlazada perezosa (lazy). Los valores se calculan solo cuando se necesitan. Debido a su naturaleza perezosa, la mayoría de las operaciones se realizan en tiempo constante. En general, las operaciones son intermedias y se ejecutan en una sola pasada.
Lo sorprendente de los streams es que podemos usarlos para representar secuencias que son (teóricamente) infinitamente largas.
// 2, 4, 6, ...
Stream.from(1).filter(i -> i % 2 == 0);3.4.3. Características de Rendimiento
| head() | tail() | get(int) | update(int, T) | prepend(T) | append(T) | |
|---|---|---|---|---|---|---|
Array |
const |
linear |
const |
const |
linear |
linear |
CharSeq |
const |
linear |
const |
linear |
linear |
linear |
Iterator |
const |
const |
— |
— |
— |
— |
List |
const |
const |
linear |
linear |
const |
linear |
Queue |
const |
consta |
linear |
linear |
const |
const |
PriorityQueue |
log |
log |
— |
— |
log |
log |
Stream |
const |
const |
linear |
linear |
constlazy |
constlazy |
Vector |
consteff |
consteff |
const eff |
const eff |
const eff |
const eff |
| contains/Key | add/put | remove | min | |
|---|---|---|---|---|
HashMap |
consteff |
consteff |
consteff |
linear |
HashSet |
consteff |
consteff |
consteff |
linear |
LinkedHashMap |
consteff |
linear |
linear |
linear |
LinkedHashSet |
consteff |
linear |
linear |
linear |
Tree |
log |
log |
log |
log |
TreeMap |
log |
log |
log |
log |
TreeSet |
log |
log |
log |
log |
Leyenda:
-
const — tiempo constante.
-
consta — tiempo constante amortizado, algunas operaciones pueden tomar más tiempo.
-
consteff — tiempo efectivamente constante, dependiendo de suposiciones como la distribución de claves hash.
-
constlazy — tiempo constante perezoso (lazy), la operación se difiere.
-
log — tiempo logarítmico.
-
linear — tiempo lineal.
3.5. Verificación de Propiedades
La verificación de propiedades (también conocida como pruebas de propiedades) es una forma realmente poderosa de probar propiedades de nuestro código de manera funcional. Se basa en la generación de datos aleatorios, que se pasan a una función de verificación definida por el usuario.
Vavr admite pruebas de propiedades en su módulo io.vavr:vavr-test, por lo que asegúrate de incluirlo para usarlo en tus pruebas.
Arbitrary<Integer> ints = Arbitrary.integer();
// square(int) >= 0: OK, passed 1000 tests.
Property.def("square(int) >= 0")
.forAll(ints)
.suchThat(i -> i * i >= 0)
.check()
.assertIsSatisfied();Los generadores de estructuras de datos complejas se componen de generadores simples.
3.6. Pattern Matching
SScala tiene coincidencia de patrones (pattern matching) nativa, una de las ventajas sobre el Java puro. The basic syntax is close to Java’sLa sintaxis básica es similar al switch de Java:
val s = i match {
case 1 => "one"
case 2 => "two"
case _ => "?"
}Notablemente, match es una expresión, lo que significa que produce un resultado. Además, ofrece:
-
Parámetros nombrados:
case i: Int ⇒ "Int " + i -
Desestructuración de objetos:
case Some(i) ⇒ i -
Condiciones de guarda (guards):
case Some(i) if i > 0 ⇒ "positive " + i -
Múltiples condiciones:
case "-h" | "--help" ⇒ displayHelp -
Verificaciones en tiempo de compilación para exhaustividad
El Pattern matching es una gran característica que nos ahorra escribir cadenas de ramas if-then-else. Reduce la cantidad de código mientras se enfoca en las partes relevantes.
3.6.1. Fundamentos de Match para Java
Vavr proporciona una API de coincidencia (match) que es similar a la de Scala. Se habilita agregando el siguiente import a nuestra aplicación:
import static io.vavr.API.*;Teniendo los métodos estáticos Match, Case y los patrones atómicos (atomic patterns)
-
$()- patrón comodín (wildcard) -
$(value)- patrón de igualdad -
$(predicate)- patrón condicional
En el alcance, el ejemplo inicial de Scala puede expresarse de esta manera:
String s = Match(i).of(
Case($(1), "one"),
Case($(2), "two"),
Case($(), "?")
);⚡ Usamos nombres de métodos en mayúsculas uniformes porque 'case' es una palabra clave en Java. Esto hace que la API sea especial.
Exhaustividad (Exhaustiveness)
El último patrón comodín (wildcard) $() nos protege de un MatchError, que se lanza si ningún caso coincide.
Debido a que no podemos realizar verificaciones de exhaustividad como lo hace el compilador de Scala, ofrecemos la posibilidad de devolver un resultado opcional:
Option<String> s = Match(i).option(
Case($(0), "zero")
);Syntactic Sugar (Azúcar Sintáctico)
Como se mostró anteriormente, Case permite coincidir con patrones condicionales.
Case($(predicate), ...)Vavr ofrece un conjunto de predicados predeterminados.
import static io.vavr.Predicates.*;Estos pueden usarse para expresar el ejemplo inicial de Scala de la siguiente manera:
String s = Match(i).of(
Case($(is(1)), "one"),
Case($(is(2)), "two"),
Case($(), "?")
);Condiciones Múltiples
Usamos el predicado isIn para verificar múltiples condiciones:
Case($(isIn("-h", "--help")), ...)Realizando Efectos Secundarios
Match actúa como una expresión y produce un valor. Para realizar efectos secundarios (side-effects), necesitamos usar la función auxiliar run que devuelve Void:
Match(arg).of(
Case($(isIn("-h", "--help")), o -> run(this::displayHelp)),
Case($(isIn("-v", "--version")), o -> run(this::displayVersion)),
Case($(), o -> run(() -> {
throw new IllegalArgumentException(arg);
}))
);⚡ run se utiliza para evitar ambigüedades y porque void no es un valor de retorno válido en Java.
Precaución: run no debe usarse como valor de retorno directo, es decir, fuera del cuerpo de una lambda:
// Incorrecto
Case($(isIn("-h", "--help")), run(this::displayHelp))De lo contrario, los Case se evaluarán de forma anticipada antes de que los patrones sean comparados, lo que rompe toda la expresión Match. En su lugar, se debe usar dentro del cuerpo de una lambda:
// Correcto
Case($(isIn("-h", "--help")), o -> run(this::displayHelp))Como podemos ver, run es propenso a errores si no se usa correctamente. Ten cuidado. Estamos considerando marcarlo como obsoleto en una versión futura y, tal vez, proporcionar una mejor API para realizar efectos secundarios.
Parámetros Nombrados
Vavr aprovecha las lambdas para proporcionar parámetros nombrados para los valores coincidentes.
Number plusOne = Match(obj).of(
Case($(instanceOf(Integer.class)), i -> i + 1),
Case($(instanceOf(Double.class)), d -> d + 1),
Case($(), o -> { throw new NumberFormatException(); })
);Hasta ahora, hemos coincidido valores directamente utilizando patrones atómicos. Si un patrón atómico coincide, el tipo correcto del objeto coincidente se infiere del contexto del patrón.
A continuación, exploraremos patrones recursivos que pueden coincidir con gráficos de objetos de profundidad (teóricamente) arbitraria.
Descomposición de Objetos
En Java usamos constructores para instanciar clases. Entendemos la descomposición de objetos como la destrucción de objetos en sus partes.
Mientras que un constructor es una función que se aplica a los argumentos y devuelve una nueva instancia, un deconstructor es una función que toma una instancia y devuelve sus partes. Decimos que un objeto está descompuesto.
La destrucción de objetos no necesariamente es una operación única. Por ejemplo, un LocalDate puede descomponerse en:
-
Los componentes de año, mes y día.
-
El valor
longque representa los milisegundos desde la época de unInstantcorrespondiente. -
etc.
3.6.2. Patrones
En Vavr usamos patrones para definir cómo se deconstruye una instancia de un tipo específico. Estos patrones pueden usarse junto con la API de coincidencia (Match).
Patrones Predefinidos
Para muchos tipos de Vavr ya existen patrones de coincidencia predefinidos. Estos se importan mediante
import static io.vavr.Patterns.*;Por ejemplo, ahora podemos coincidir con el resultado de un Try:
Match(_try).of(
Case($Success($()), value -> ...),
Case($Failure($()), x -> ...)
);⚡ Un primer prototipo de la API de coincidencia (Match) de Vavr permitía extraer una selección definida por el usuario de objetos a partir de un patrón de coincidencia. Sin el soporte adecuado del compilador, esto no es práctico porque el número de métodos generados crecía exponencialmente. La API actual hace un compromiso: todos los patrones se coinciden, pero solo los patrones raíz son descompuestos.
Match(_try).of(
Case($Success($Tuple2($("a"), $())), tuple2 -> ...),
Case($Failure($(instanceOf(Error.class))), error -> ...)
);Aquí los patrones raíz son Success y Failure. Estos se descomponen en Tuple2 y Error, teniendo los tipos genéricos correctos.
⚡ Los tipos profundamente anidados se infieren según el argumento de Match y not según los patrones coincidentes.
Patrones Definidos por el Usuario
Es esencial poder descomponer objetos arbitrarios, incluidas las instancias de clases finales. Vavr hace esto de forma declarativa al proporcionar las anotaciones en tiempo de compilación @Patterns y @Unapply.
Para habilitar el procesador de anotaciones, el artefacto vavr-match debe añadirse como dependencia del proyecto.
⚡ Nota: Por supuesto, los patrones pueden implementarse directamente sin usar el generador de código. Para más información, consulta el código fuente generado.
import io.vavr.match.annotation.*;
@Patterns
class My {
@Unapply
static <T> Tuple1<T> Optional(java.util.Optional<T> optional) {
return Tuple.of(optional.orElse(null));
}
}El procesador de anotaciones coloca un archivo MyPatterns en el mismo paquete (por defecto en target/generated-sources). También se admiten clases internas. Caso especial: si el nombre de la clase es $, el nombre de la clase generada será simplemente Patterns, sin prefijo.
Guardas (Guards)
Ahora podemos coincidir con objetos Optionals utilizando guards.
Match(optional).of(
Case($Optional($(v -> v != null)), "defined"),
Case($Optional($(v -> v == null)), "empty")
);Los predicados podrían simplificarse implementando isNull y isNotNull.
⚡ ¡Y sí, extraer un null es extraño! En lugar de usar el Optional de Java, prueba con la Option de Vavr.
Match(option).of(
Case($Some($()), "defined"),
Case($None(), "empty")
);4. License
Copyright 2014-2025 Vavr, https://vavr.io
Licenciado bajo la Licencia Apache, Versión 2.0 (la "Licencia");
no puedes usar este archivo excepto en cumplimiento con la Licencia.
Puedes obtener una copia de la Licencia en:
A menos que lo exija la ley aplicable o se acuerde por escrito, el software distribuido bajo la Licencia se distribuye "TAL CUAL",
SIN GARANTÍAS O CONDICIONES DE NINGÚN TIPO, ya sean expresas o implícitas.
Consulta la Licencia para conocer los permisos y las limitaciones bajo la Licencia.